
Activity Feed › Discussion Forums › Strictly Surveying › Looking for a bit of peer review… (error propagation)
Looking for a bit of peer review… (error propagation)
Posted by bc-surveyor on December 7, 2022 at 10:15 pmHello, earlier this week I made a thread asking for advice on some equations for determining the random error of a total station measurement. I’ve spent a few days going through textbooks and looking at papers online and think I’ve come up with a worksheet (attached .xlsx file) and explanation (attached .pdf file) that seems to do what I set out to.
If you open the spreadsheet, the front page is editable, input your survey measurement values and instrument/equipment specs and it will kick out the random error propagated from those measurements and instrument specs.
The PDF explains the equations I used and assumptions I made.
The goal in making this was to help explain to less experienced field techs the actual error we can expect from our measurements. It’s a pet peeve of mine when someone sets up and does a check and by chance it lands within 1mm of the given coordinate that they assume they are now surveying to within 1mm on every subsequent shot. I see this far too often and am hoping I can use this worksheet as a teaching aid. It could also be useful to explain to clients how their +/- 1mm accuracy request may not be realistic & to determine what equipment/methodology is needed given a realistic required survey accuracy.
If you see any issues with the equations or my assumptions please let me know and if I agree than I will make the changes and upload the spreadsheet to my website where it will be available to anyone for free. I still have some data entry to add more prism types and I am debating whether or not to add cells to take into account existing control error.
I really appreciate any that take the time out of your busy schedules to go through this.
jaccen replied 1 year, 4 months ago 8 Members · 21 Replies- 21 Replies

Nice looking spreadsheet. I haven’t checked any of the formulas.
Picky comment: I don’t like the label sigma95%. Sigma has a usual meaning and is not usually qualified at various confidence levels. I would call it E95%, 95% Conf or something else.
Shouldn’t you put +/- label on the E and N values for clarity?
The factor from rms to 95% for a 1-dimensional normal variable, like elevation is 1.96 (not 2).
If E and N sigma are equal, you get a Rayleigh distribution for the radial horizontal error, and the probability of being within one of those sigmas radially is only 39.3% and radius=sqrt(2)*sigma is 63.2%. You don’t do sqrt(sum(squares)) and use the normal table.
And it’s a lot more complicated if sigmaN and sigmaE aren’t equal or if they are correlated.
.
Nice looking spreadsheet. I haven’t checked any of the formulas.
Picky comment: I don’t like the label sigma95%. Sigma has a usual meaning and is not usually qualified at various confidence levels. I would call it E95%, 95% Conf or something else. – Good point, I will adjust this.
Shouldn’t you put +/- label on the E and N values for clarity? – Correct, I will adjust this too.
The factor from rms to 95% for a 1-dimensional normal variable, like elevation is 1.96 (not 2). – That’s right, what I was calculating was actually 95.XXX%. I will change the multiple to 1.96.
If E and N sigma are equal, you get a Rayleigh distribution for the radial horizontal error, and the probability of being within one of those sigmas radially is 60.6%. You don’t do sqrt(sum(squares)). And it’s a lot more complicated if they aren’t equal or if they are correlated. – I’m lost here, I think what you’re saying is ?Hz Pos= ?? ?N2+ ?E2 is not correct? If so, how do I calculated the standard deviation of the horizontal position?
I edited the last paragraph while you were posting. It’s complicated and I don’t know an easy way to get the values in general.
Maybe we can get some help from @mathteacher
.I think I finally got it…
Hz Pos = ?? (??N)2 + (??E)2
Using error propagation, we can determine the standard deviation of the relative easting of the measured point (?E) is equal to;
???Hz Pos = ??((????Hz Pos/????N)2 * ???N2 + (????Hz Pos /????E)2 * ???E2)
(????Hz Pos/????N) = ??N / ?? (??N2 + ??E2)
(????Hz Pos/????E) = (??E / ?? (??N2 + ??E2))
???Hz Pos = ??(((??N / ?? (??N2 + ??E2))2 * ???N2 + (??E / ?? (??N2 + ??E2))2 * ???E2))

The goal in making this was to help explain to less experienced field techs the actual error we can expect from our measurements. It’s a pet peeve of mine when someone sets up and does a check and by chance it lands within 1mm of the given coordinate that they assume they are now surveying to within 1mm on every subsequent shot. I see this far too often and am hoping I can use this worksheet as a teaching aid. It could also be useful to explain to clients how their +/- 1mm accuracy request may not be realistic & to determine what equipment/methodology is needed given a realistic required survey accuracy.
I once had to re-stake a ROW that changed and was following and setting up on the previous persons traverse points and they were checking at almost a tenth each setup. I can??t imagine what they??re closure would be like ????

I often get in trouble with error propagation calculations, so I’ll defer to Bill and not comment on the math. But here are two questions from reading the PDF.
1. Pointing and reading. If the manufacturer’s stated SD is for a single direction only, why do you have to adjust it if all you do is a single direction observation? Adjusting for two pointings makes sense but adjusting for only one seems to violate your description of the parameter.
2. In the Conclusion: “…we should usually err on the side of safety and use 95% confidence depending on what the layout is for.” Are you sure that using 95% confidence interval is erring on the side of safety? Consider Type I and Type II errors when you design a statistical test. The wider the confidence interval, the greater your chance of accepting a bad result, saying that the null hypothesis is true when it’s actually false.
In that regard, what is the null hypothesis that you’re testing? For example, if your observations say that the azimuth to the point is 65 degrees, is AZ = 65 degrees your null hypothesis? How do you then use your formula derived SDs to verify that? If your formula derived SD is 3 seconds, how are you going to use that?
To Bill’s point, the proper distribution is key. Most survey measurements that I’ve looked at don’t meet the minimum of 30 observations required for using the Normal Distribution. But suppose you do 40 observations, your mean is 64 degrees, 5 seconds and your sample SD is 2 seconds, what claim are you going to make?
The only claim that I could make is that I’m about 68% sure that AZ is between 64 degrees, 3 seconds and 64 degrees,7 seconds and that I’m about 95% sure that AZ is between 64 degrees, 1 second and 64 degrees, 9 seconds.
That extra bit of confidence comes at the expense of widening the acceptable range. The caution here is applicable to the surveyor, not the client.
As I said, I get into trouble with error calculations, so somebody correct me if I’m wrong.
I often get in trouble with error propagation calculations, so I’ll defer to Bill and not comment on the math. But here are two questions from reading the PDF.
1. Pointing and reading. If the manufacturer’s stated SD is for a single direction only, why do you have to adjust it if all you do is a single direction observation? Adjusting for two pointings makes sense but adjusting for only one seems to violate your description of the parameter.
Im not sure I totally understand. The only time you’ll ever be doing a single direction observation would be with a zenith angle and you are only pointing and reading once (which I do make note of, and technically it is still adjusted by 1/?? n). The other edge of the angle is determined by gravity, technically this should be taken into account with the accuracy of how well you levelled the instrument but the quantity is neglidgable. If Im turning to a point horizontally, there are two pointings and two readings. One at the backsight and one at the foresight. A pointing/reading direction wont tell you anything horizontally if it’s not referenced to anything.
2. In the Conclusion: “…we should usually err on the side of safety and use 95% confidence depending on what the layout is for.” Are you sure that using 95% confidence interval is erring on the side of safety? Consider Type I and Type II errors when you design a statistical test. The wider the confidence interval, the greater your chance of accepting a bad result, saying that the null hypothesis is true when it’s actually false.
Erring on the side of safety as in at 95% confidence our measurement will be more inaccurate, therefor we must tighten up the parameters we can to ensure our measurement is better/more accurate.
Ex. if we measure a line +/- 0.1m at 68% confident then at 95% confidence we measured that line to within +/- 0.196m. If we have a specification that we measure the line to within 0.1m then we must do a better job of measuring that line if we want to obtain 95% confidence.
In that regard, what is the null hypothesis that you’re testing? For example, if your observations say that the azimuth to the point is 65 degrees, is AZ = 65 degrees your null hypothesis? How do you then use your formula derived SDs to verify that? If your formula derived SD is 3 seconds, how are you going to use that?
To Bill’s point, the proper distribution is key. Most survey measurements that I’ve looked at don’t meet the minimum of 30 observations required for using the Normal Distribution. But suppose you do 40 observations, your mean is 64 degrees, 5 seconds and your sample SD is 2 seconds, what claim are you going to make?
The only claim that I could make is that I’m about 68% sure that AZ is between 64 degrees, 3 seconds and 64 degrees,7 seconds and that I’m about 95% sure that AZ is between 64 degrees, 1 second and 64 degrees, 9 seconds.
That extra bit of confidence comes at the expense of widening the acceptable range. The caution here is applicable to the surveyor, not the client.
As I said, I get into trouble with error calculations, so somebody correct me if I’m wrong.
Im confused here as well, my apologies. I dont really care too much how about the standard deviation of my azimuth other than how that factors into the error propagation of my final coordinates as that is what really matters in the end.
Thanks for the response.
I am still scratching my head if I did the final ??Hz Pos standard devation calculation correctly. The math seems to make sense but it means my error in my ??HZ pos will never be more than the larger error of either my ??N or ??E which im having a hard time visualizing.
I interpreted your single face observation, where you divided by sqrt(0.05) as being a single observation.
It seems that you want the sample variance/standard deviation of a measurement made up of many variable items to meet some set value within a certain tolerance range. Is your formula calculated value what you’re comparing to? If so, the proper distribution is Chi square.
Your example with +/- 0.1 meter at 68% confidence says that your standard deviation is 0.1 meter. I think we would agree that to be 95% confident in that range, SD would have to be 0.051. In order to achieve that, wouldn’t you have to look at the SDs of the components to see where your greatest improvement could be made?
These are measures of precision, not accuracy. Suppose your first measurements with 0.1-meter SD had a mean of 200.000 meters and your improved measurements had an SD of 0.049 meter with a mean of 199.987 meters.
The two distributions overlap, one meets your SD requirement, both contribute data. Do you ignore one and keep the other, do you combine them, do you throw out some measurements? How do you determine the value to report?
My AZ example applies to your final result as well, but you answered that for both also.
Otherwise, I always try to keep couple of things in mind. A statistical distribution is determined by its mean and its standard deviation and that changing either changes the distribution. All data subjected to statistical analyses is sample data; we never know what the universe data is. A predetermined value for any parameter contains many assumptions that may or may not conform to measurement assumptions.
You always have to choose one value and that number has to be “right enough.” Statistics can help but there are no guarantees.
I interpreted your single face observation, where you divided by sqrt(0.05) as being a single observation.
If the standard deviation of a an instrument is +/- 3″ that means that’s how precise it is for a single direction in f1 + f2 to 68% confidence. Lets look at the equation for the mean.
x?? +/- Z *? / ??n
We can see the standard deviation of the mean, of a direction in this case, is the following equation. 2 because that’s already built into the mfc. specs.
?d = ?d1 / ??2
When were taking two measurements to the same point (f1 +f2) were getting the mean. In this case we have the stated standard deviation of 3″. So if we wanted the standard deviation of a single face, single direction (?d1) it would be 3 * ??2 or 4.24″ and if we wanted ?Ag1 it would be 6″. It must also be said that taking f1 + f2 observations removes many systematic errors, so this equation only holds true if those have be corrected with proper calibration. In reality the value is going to be worse.
?Ag1 = ??((?d2)2 + (?d1)2
It seems that you want the sample variance/standard deviation of a measurement made up of many variable items to meet some set value within a certain tolerance range. Is your formula calculated value what you’re comparing to? If so, the proper distribution is Chi square.
I want to determine the standard deviation of a measurement made up of many variables. I don’t want it to meet this or that. The purpose of this exercise is to determine the standard deviation of the change in coordinates, or the relative precision of a point. Excuse my ignorance but I dont understand what you mean in your last sentence there. I thought a Chi square test determines if two values are statistically the “same”? I’m not trying to do that here. More so just some basic analysis.
Your example with +/- 0.1 meter at 68% confidence says that your standard deviation is 0.1 meter. I think we would agree that to be 95% confident in that range, SD would have to be 0.051. In order to achieve that, wouldn’t you have to look at the SDs of the components to see where your greatest improvement could be made?
Absolutely, hence the excel spreadsheet I attached. It allows one to alter the variables we can control to meet a specified precision. So when I’m project planning for a task I can decide if I need to use my 1″ instrument instead of my 5″ instrument, or obtain better reflectors, or limit my observation length to X meters, or use a mini with a HT of 0.100m, or observe n sets, ect
These are measures of precision, not accuracy. Suppose your first measurements with 0.1-meter SD had a mean of 200.000 meters and your improved measurements had an SD of 0.049 meter with a mean of 199.987 meters.
The two distributions overlap, one meets your SD requirement, both contribute data. Do you ignore one and keep the other, do you combine them, do you throw out some measurements? How do you determine the value to report?
In that example I then I would weight my observations by the inverse of the standard deviation. AKA least squares. Which would be the next step in determining the measurement. All Im trying to do here is some error propagation to figure out how good my measurements are so I can analyze if they’re good enough according to my/the clients needs.
My AZ example applies to your final result as well, but you answered that for both also.
Otherwise, I always try to keep couple of things in mind. A statistical distribution is determined by its mean and its standard deviation and that changing either changes the distribution. All data subjected to statistical analyses is sample data; we never know what the universe data is. A predetermined value for any parameter contains many assumptions that may or may not conform to measurement assumptions.
You always have to choose one value and that number has to be “right enough.” Statistics can help but there are no guarantees.
Of coarse not, all we can ever hope for in surveying is “right enough”. But how can we determine that without error propagation and statistics?
Thank you again for your thoughtful response. Anything I’m writing is me thinking out loud so please punch holes in my thought process if I’m wrong anywhere, I usually am.
The variances of samples drawn from a normal distribution follow the Chi square distribution. Look here for more:
1.3.5.8. Chi-Square Test for the Variance (nist.gov)
“In this case we have the stated mean of 3″.” Wait. I thought this was the SD of F1+F2 measurements. You’re somehow taking the standard error of the mean of two observations (F1 and F2) and claiming to be able to calculate the standard deviations of the individual measurements. Let’s go a step further. What are the means of the individual F1 and F2 measurements? Isn’t the standard deviation a function of the mean? There will be less variation in means than in individual measurements, but I’m not sure if determine the variance of the individuals from the variance of their means
If you’re not trying to meet some standard, how do you know if your measurements are good enough for your client?
In that example I then I would weight my observations by the inverse of the standard deviation. What if the order of the two samples were reversed so that you got the one that meets the SD requirement (what?) first. Would you have reported 199.987 meters as the distance? The weighted observations would produce a different result.
I’m not a surveyor and you’ve taught me some things with this exchange. Asking questions about the math applications is just an old teacher’s habit to help with overall understanding and eliminate misconceptions on everybody’s part.
Keep it going, others are probably considering the questions, too.
The variances of samples drawn from a normal distribution follow the Chi square distribution. Look here for more:
1.3.5.8. Chi-Square Test for the Variance (nist.gov)
“In this case we have the stated mean of 3″.” Wait. I thought this was the SD of F1+F2 measurements.
I meant standard deviation, my mistake. I’ve changed it in my earlier response.
You’re somehow taking the standard error of the mean of two observations (F1 and F2) and claiming to be able to calculate the standard deviations of the individual measurements.
Yes. Do the equations of error propagation not support this? Can you point to one of the equations I’m using that is incorrect or being used incorrectly? I believe this is the best method I have to do this given the data I have available, if not, im all ears?
Let’s go a step further. What are the means of the individual F1 and F2 measurements? Isn’t the standard deviation a function of the mean? There will be less variation in means than in individual measurements, but I’m not sure if determine the variance of the individuals from the variance of their means
That’s a good point. The standard deviation could be a function of the mean. However, can the standard deviation also not be approximated using error propagation? If not, then must we ignore error propagation all together?
If you’re not trying to meet some standard, how do you know if your measurements are good enough for your client?
I guess I worded my previous response ambiguously, you are right. But the main purpose of this exercise is to determine the relative precision of the coordinates of a point. If I’m analyzing the data wrong, that’s completely possible but I don’t believe that is directly tied to the equations?
In that example I then I would weight my observations by the inverse of the standard deviation. What if the order of the two samples were reversed so that you got the one that meets the SD requirement (what?) first. Would you have reported 199.987 meters as the distance? The weighted observations would produce a different result.
It has been 10+ years since I’ve done any manual least squares calculations back in University, these days I leave that to StarNet, admittedly I should know exactly how it works and after this maybe I delve into the nitty gritty of that, but I dont believe the order of observations bear any weight of the derived result. I fairly certain but could be wrong.
I’m not a surveyor and you’ve taught me some things with this exchange. Asking questions about the math applications is just an old teacher’s habit to help with overall understanding and eliminate misconceptions on everybody’s part.
I appreciate it, it’s forcing me to have a better understanding of what I’ve regurgitated on paper to go back and really think about it.
Keep it going, others are probably considering the questions, too.

There is a article in XYXht magazine I believe if my memory is holding up written by Ghillianie i read at some point in the past. Wish I could remember what year. I think he had a couple parts on it about some of this. He gave some examples etc. might be worth a quick search. I am awaiting a desk and book shelves at my office who knows when they will arrive but I believe i printed out several articles along this very topic at one time. I am a pack rat sorta. I have equation and books from my first year in surveying. Still have a note card (math teacher) would probably get a kick out of. I had formulas written on it that fit in my hp32sII case. (My college tutor in math helped me make the formula card) Went everywhere with me in my early days of surveying. If i come across anything i will get it to you. Was that pdf any help. I am so busy feeding cows and surveying i have little time to fire up the old laptop to find more things i have sav d.
Where’s Kent when you need him?
.but I dont believe the order of observations bear any weight of the derived result. My point here is that, had the first sample met your criteria, the second would never have been done. If you weight the first and second samples, you’ve changed your procedure according to the order of potential samples. If I’m good first time through, then I’m good. If not, I’ll apply a judgmental weighting to those measurements and add some more with a different weighting until I’m good.
The sigma over the sqrt(n) is a consequence of the Law of Large Numbers. It says that as sample sizes get larger, the sample mean approaches the population mean ever closer. The limit of the sample mean as the sample size approaches infinity is the population mean. The sample size, n, is an integer. I don’t think that there’s a provision for a fractional sample size. Thus, I can’t see a justification for the use of 1/sqrt(0.5). In any case, the formula assumes that the SDs of F1 and F2 are equal, which they may not be.
I wouldn’t discourage the effort; what you’ve done already is more than I could do.
Always, always keep the big statistical picture in mind. One of the most talented PhD statisticians I ever worked with started every job with a simple box plot.
He’d be all over it, wouldn’t he?
I gave up on the std dev. of the delta hz pos equations. They just weren’t making sense to me.
Instead I did the coordinate error ellipse at 95% and plotted it on the spreadsheet. That was a much easier calculation and actually might be more useful to know. It checks out well with my E95% delta northing and easting which were calculated independently so Im fairly happy things are on the right track.
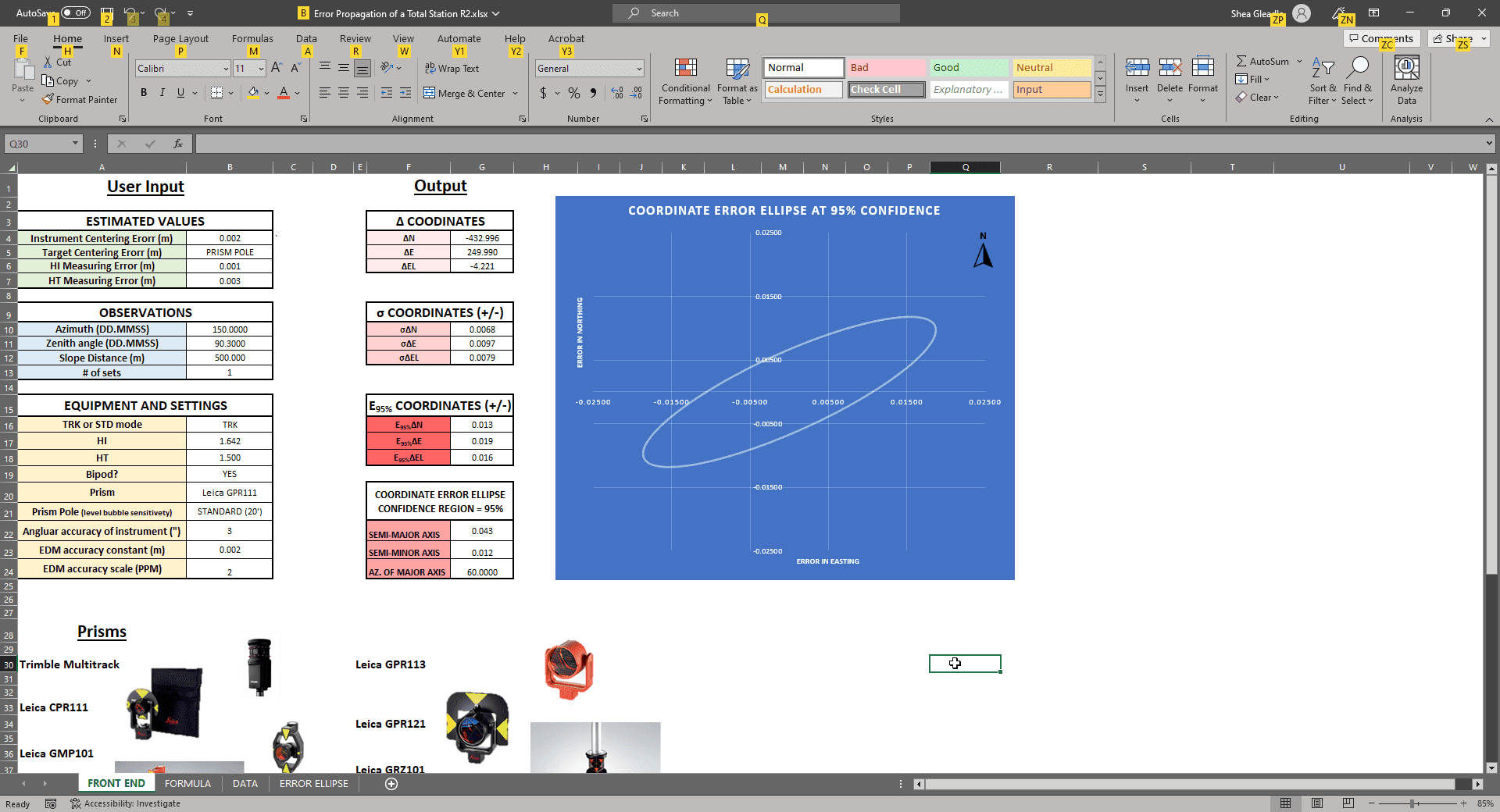
**EDIT**
I screwed up the error ellipse formula and have updated the .xlsx. I was using the std dev of HD not HDt.

I was thinking the same thing. Didn’t Kent do a pretty exhaustive series of posts back on POB about real world techniques for error estimating and least squares setups?
And isn’t all this covered in the Star*Net software that is now part of Microsurvey? Why re-invent the wheel?


Why re-invent the wheel?
I hope everyone has a great day; I know I will!I was thinking the same thing. Didn’t Kent do a pretty exhaustive series of posts back on POB about real world techniques for error estimating and least squares setups?
And isn’t all this covered in the Star*Net software that is now part of Microsurvey? Why re-invent the wheel?
An easier GUI and more widely available, free to everyone.
https://www.youtube.com/watch?v=-iibpfjrxlo
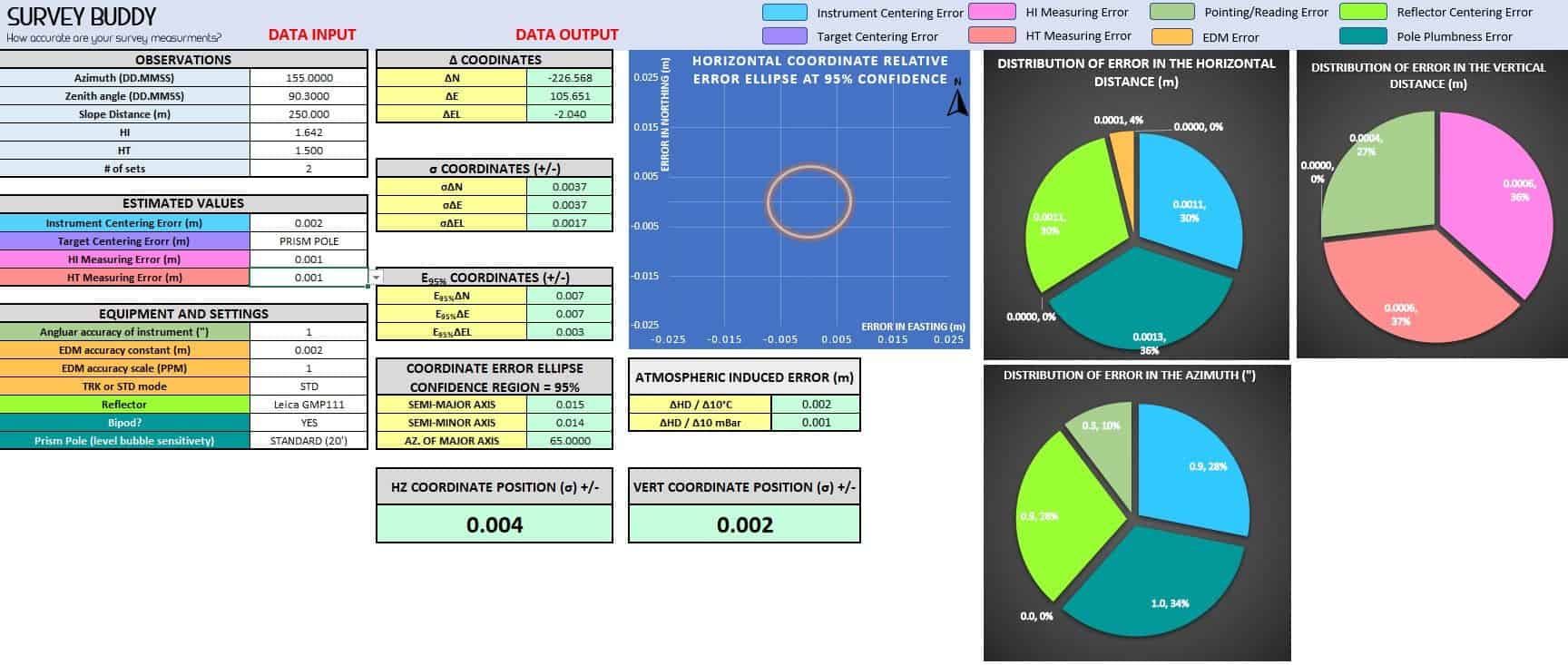
Version 1 is all done. I may revisit this in a few months with some ideas I have for additional features.


Log in to reply.